
Webページの閲覧
URL
- ホームページは、ブラウザでURL(Uniform Resource Locator)を指定することによって、閲覧できる。
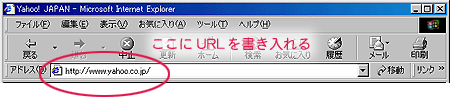 |
- ドメイン名は、ネットワークに接続されたサーバ・コンピュータに割り当てられたアドレス(コンピュータの住所のようなもの)。
- パスは、目的のファイルが保存されているサーバ・コンピュータ内の階層(コンピュータ内での置き場所)。
| プロトコル | ドメイン |
パス |
ファイル名 |
||
(例)http://www. |
asa.hokkyodai. |
ac. |
jp |
/~ueda/ |
index.html |
|
組織名 |
種別 |
国名 |
|
|
InternetExplorerのボタンの機能
 |
|
戻る |
直前に表示したページを表示する。 |
進む |
「戻る」ボタンで前のページに戻っているとき、そのページの次のページを表示する(1度も表示したことのないページには使えない)。 |
中止 |
実行中のページ転送を中止する。 |
更新 |
現在のページを読みなおす。 |
ホーム |
最初に表示するよう設定したページに戻る。 |
検索 |
キーワードを指定して、Webページを検索する。 |
お気に入り |
よく見るWebページのURLを記憶させる。 |
履歴 |
これまで開いたページのリストを表示する。 |
メール |
メールソフトを起動する。 |
印刷 |
現在のページを印刷する。 |
検索エンジンの使い方
- 知りたい情報が掲載されたホームページがあるかどうか、またそのホームページのURLは何かを知りたいとき、検索エンジンを利用するとよい。
- 日本語の検索エンジンには次のようなものがある。
Yahoo Japan |
|
goo |
|
Excite |
|
Infoseek |
分類型の検索エンジン-yahooを例に-
- 分類登録によるデータベースから検索を行っているため、カテゴリーによる適切な検索や、絞り込みが容易。
 |
自動収集型の検索エンジン-gooを例に-
- 自動でWebページを収集して、データベースを構築しているため、ヒット数が分類型に比べて、圧倒的に多いが、関係のないページがヒットすることも多い。
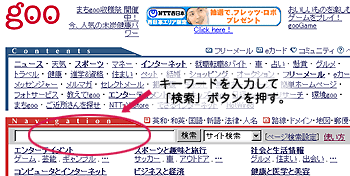 |
ページの情報を保存する
ページ全体の保存
1.保存したいWebページを開いた状態で、「ファイル」メニューの「名前を付けて保存」を選ぶ。
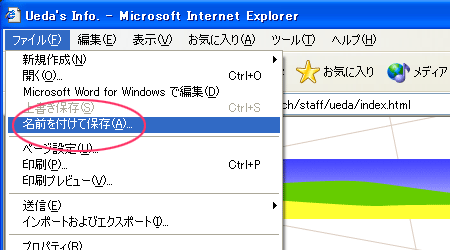 |
2.ダイアログのうち、「保存先」、「ファイルの種類」、「ファイル名」を入力して、保存する。
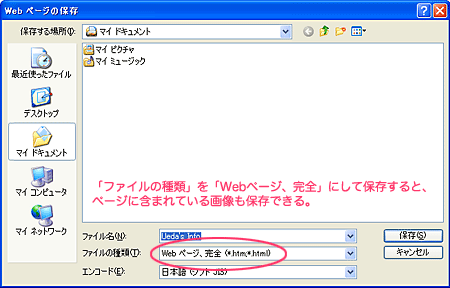 |
3.HTMLファイルと画像の入ったフォルダの両方を保管しておく。
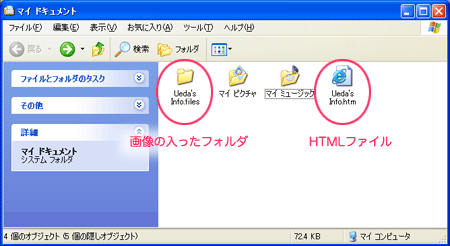 |
テキスト(文字)情報の保存
1.ワープロソフトを起動する。
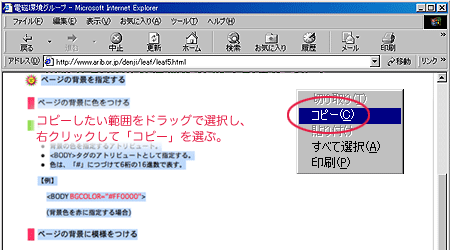
2.保存したいWebページを開き、保存したいテキストの範囲をドラッグで選択した状態で右クリックする。
3.「コピー」を選択する。
- 右クリックの代わりに「編集」-「コピー」を選択してもよい
 |
4.ワープロソフトの画面を開く。
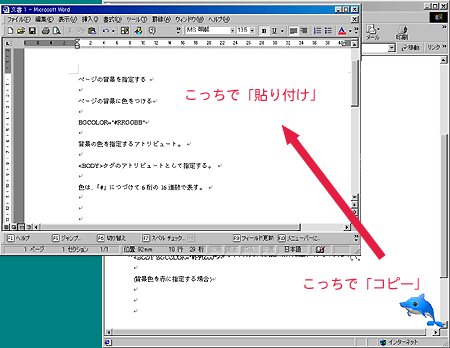
5.コピーした情報を貼り付けたい場所で、右クリックする。
6.「貼り付け」を選択する。
- 右クリックの代わりに「編集」-「貼り付け」を選択してもよい。
 |
7.貼り付けたファイルを、保存する。
画像の保存
インターネットの画像の利用にあたっては、著作権に配慮すること。特に、サイト内に画像の画像に関する注意が示してあることがあるので、注意すること。
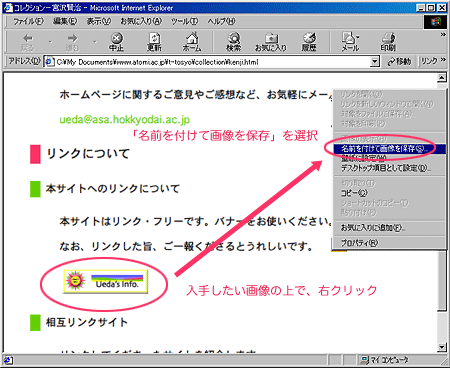
1.保存したいWebページを開き、コピーしたい画像を、マウスの右ボタンで押す。
2.出てきたダイアログの中から「名前を付けて画像を保存」を選択する。
 |
3.保存先・ファイル名を入力して保存する。
- 保存した画像ファイルは、ワープロに貼りつけることができる。